

Core ML 是 Apple 在開發機器學習上的一種框架。這工具在一年前發表,為開發者提供一個方法,只需要寫幾行程式碼,就可以將第三方強大與機敏的機器學習功能整合到自己開發的 App。今年在 2018 WWDC 的大會上,Apple 又發表了 Core ML 2.0。這最新的版本強調開發過程的流暢性,包括最佳化機器學習模型大小,改善執行的效能,並提供開發者客製化自己的 Core ML 模型。
在這次教學中我將教你所有 Core ML 2.0 新增加的功能,並且告訴你如何在你的 App 上運用它。若你對 Core ML 完全陌生,我建議你先參考本篇教學。若你已熟悉 Core ML,讓我們就此開始吧!
簡述
目前在 App Store 中有許多很棒的 App,它們都具備強大的功能,例如:你可能發現有的 App 能認知文字 (Text),或者的 App 能根據你設備上的移動,就能判斷你想要做什麼。更進一步,有的 App 能根據較早的影像,自動用濾鏡來處理你現有的影像。這些 App 都有一個共同點:它們都是機器學習的例子,而所有這些範例都可用 Core ML 模型來開發。
資料來源: Apple
Core ML 讓開發者很容易將機器學習模型整合在自己的 App 中。你可以創建一個認知對話內容或辨識聲音的 App。而且,Apple 讓開發者可以利用 Vision 和 Natural Language 這兩個框架,只要些許額外步驟就可以使用即時影像分析與自然語言辨識功能。
運用 VNCoreMLRequest 與 NLModel API,你可以大大增加 App 的 ML 功能,因為 Vision 與 Natural Language 框架已內建在 Core ML 中。
今年 Apple 集中於三點來協助 Core ML 開發者:
- 模型的大小
- 模型的效能
- 客製化模型
讓我們來探索這三點吧 !
模型的大小
Core ML 最大的優點就是所有的功能都在裝置中執行。這樣,App 若在其他地方執行運算時,也能確保使用者資料的隱私。然而,當更多精確的機器學習模型被匯入使用時,它們需要耗用更多的儲存空間。 在你的 App 中匯入這些模型後,將來使用者在安裝此 App 時,會佔用裝置很多的空間。
於是 Apple 決定提供工具,讓開發者來量化 ML 模型大小。量化一個模型即是用來計算儲存數據、以便壓縮模型佔用容量的技巧。任何機器學習模型的核心,就只是一個試著計算產生數據的機器。如果我們能減少這些數據或是能以較少的空間儲存數據,就能大大減少模型的大小,這樣可以降低執行 App 時的記憶體使用空間,也同時加快計算速度。
關於機器學習模型的組成可分為三個主要的部分:
- 模型的數量
- 權重 (weight) 的數量
- 權重的大小
當量化一個模型時,我們可減少 ML 模型權重的大小!在 iOS 11 平台上,Core ML 模型以 32 位元儲存;但在 iOS 12 平台上,Apple 讓我們能以 16 位元或 8 位元來儲存模型!這就是我們在本教學中的重點。
若你不熟悉權重,這裡有一個很棒的比喻。例如說,你準備從家裡出發到超市。第一次你可能會走某些路徑,而第二次你會試著找一條捷徑到超市,因為你已經知道到超市怎麼走。在第三次你甚至會走更短的捷徑到超市,因為你早已知道之前到超市的那 2 條路徑。每次你到超市,經由時間的學習,你會繼續找出更短的捷徑!像這樣知道該走那一條路徑到超市的知識,就是權重。所以最短的路徑,就是權重較大的路徑。
現在就讓我們來依此實作練習,寫一些程式 !
權重的量化
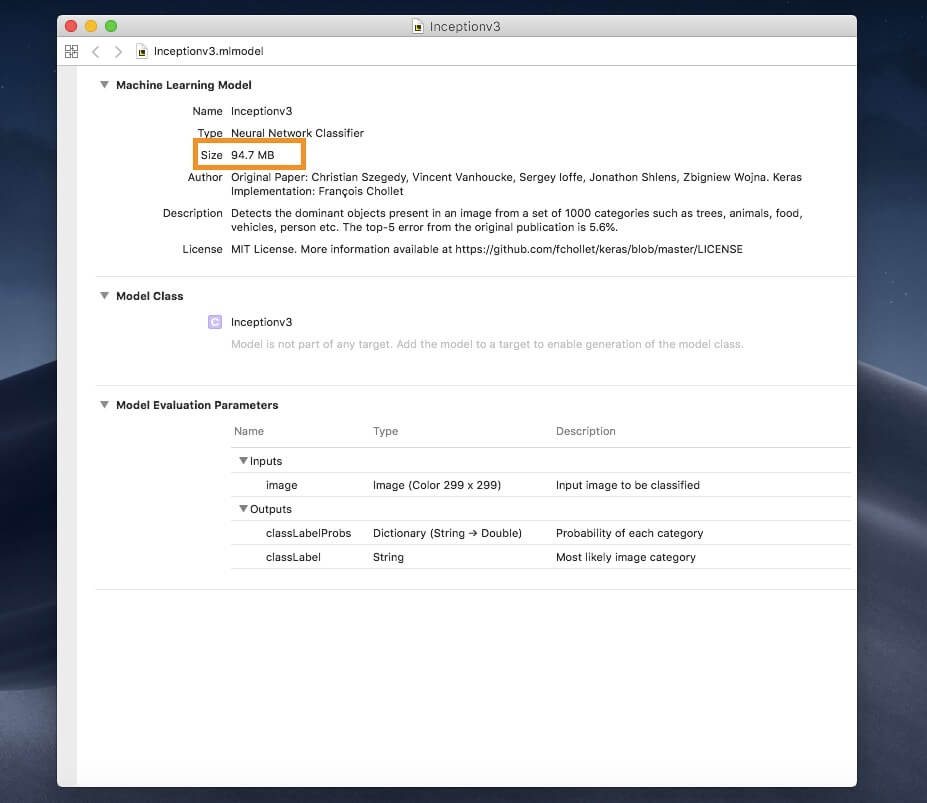
我們拿一個被廣泛使用的機器學習模型 Inception v3 來演釋。你可以從這裡下載以 Core ML 格式存取的範例。
打開這模型,你將看到它使用了 94.7 MB 的儲存空間,容量頗大。
我們將使用 Python 套件 coremltools 來量化這模型。讓我們試試看如何實作 !
假如你沒有在你的裝置上安裝 python 或 pip,你可以參考這篇文章來學習安裝過程。
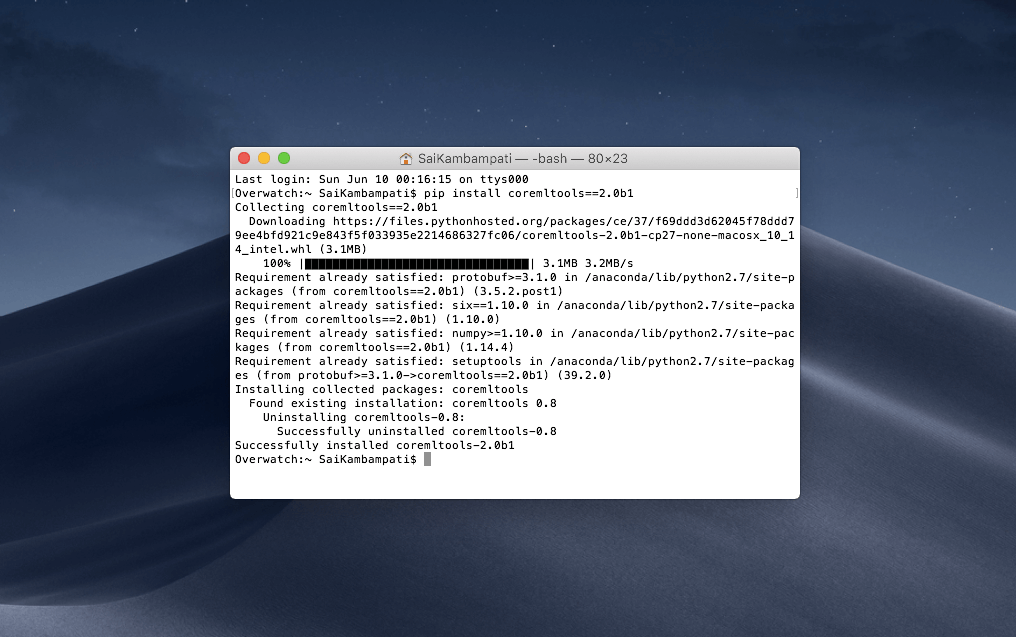
首先你需要確認已安裝 beta 版本的coremltools。開啟命令視窗,並輸入下列程式碼:
pip install coremltools==2.0b1
輸入後,你將看到這樣的輸出:
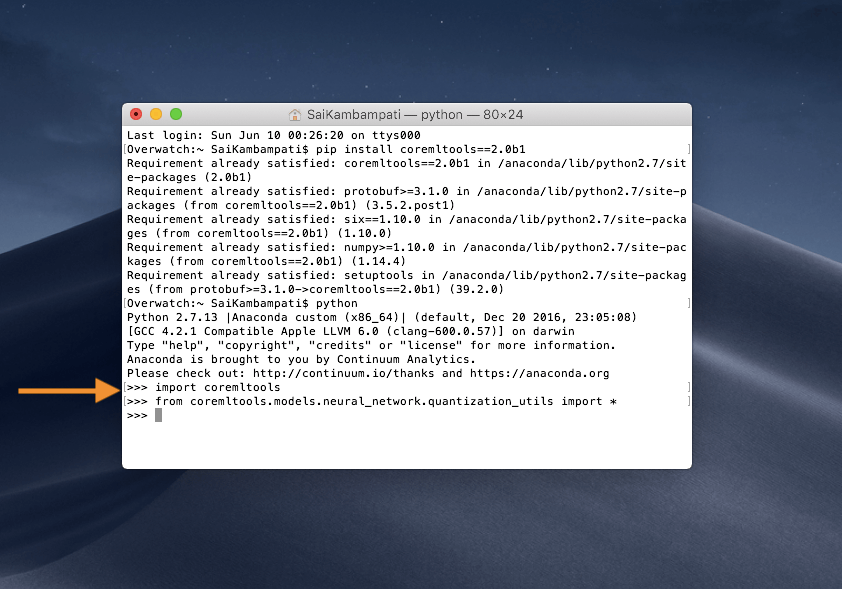
這表示你已成功安裝 Core ML Tools 的 beta 1 版本。接下來幾個步驟你須懂一點 Python,不過,不用擔心,這很簡單,而且不需要寫太多程式碼。開啟你的 Python 編輯工具或在命令列視窗中輸入下列指令。首先,讓我們匯入 (import) coremltools 套件。在命令列視窗中輸入 python 這指令,然後當編輯視窗出現時,輸入下列指令:
import coremltools
from coremltools.models.neural_network.quantization_utils import *
這樣做就可以把 Core ML 套件和全部量化工具都匯入到程式中。接下來,讓我們定義一個變數 model,並且為它指定剛剛下載的 URL Inceptionv3.mlmodel。
model = coremltools.models.MLModel('/PATH/TO/Inceptionv3.mlmodel')
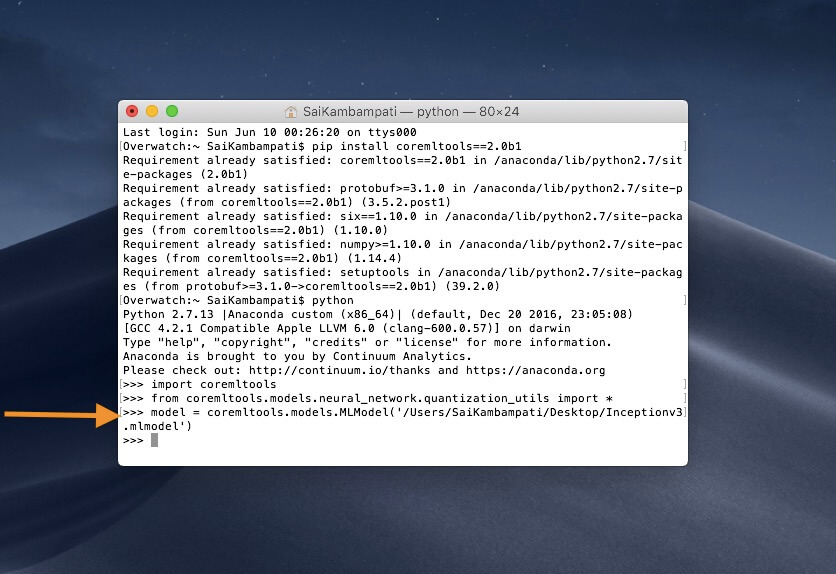
在我們量化模型之前(這只需要兩行程式碼),讓我先教你神經網路的一些背景知識。
一個神經網路是由不同的層別 (Layer) 所組成,這些層別僅僅是有許多參數的數學函數,而這些參數就是已知的權重。
資料來源:Towards Data Science
當我們在量化權重時,我們會拿權重最小與最大的數值,然後建立一個函數映射關係。要建立這樣的函數映射有許多方法,但最常用的就是權重線性映射 (Linear Quantization) 與權重查表 (Table Quantization)。權重線性映射量化就是平均將權重做線性分佈,以減少權重的數量;而權重查表方法即是替模型建立一張對照表,並依據相似度來歸納成一組,這樣才能減少權重的數量。
如果這樣聽起來很複雜,別擔心。我們只需要決定我們 ML 模型的資料由幾個位元組成、以及選用何種演算方法。首先,讓我們先試試採用線性量化一個模型,看看會有什麼結果。
lin_quant_model = quantize_weights(model, 16, "linear")
上面的程式碼量化了範例模型 Inceptionv3 的權重。這模型的資料由16位元所組成,而採用的是線性量化權重的方法。執行程式碼,你將看到這程式針對每個層別,顯示ㄧ連串被量化的權重數據。

讓我們保存這模型,再與原來的模型做個比較。先指向我們原先儲存模型的路徑,並輸入下列指令:
lin_quant_model.save('Path/To/Save/QuantizedInceptionv3.mlmodel')
現在開啟這兩個模型,比較它們的檔案大小。
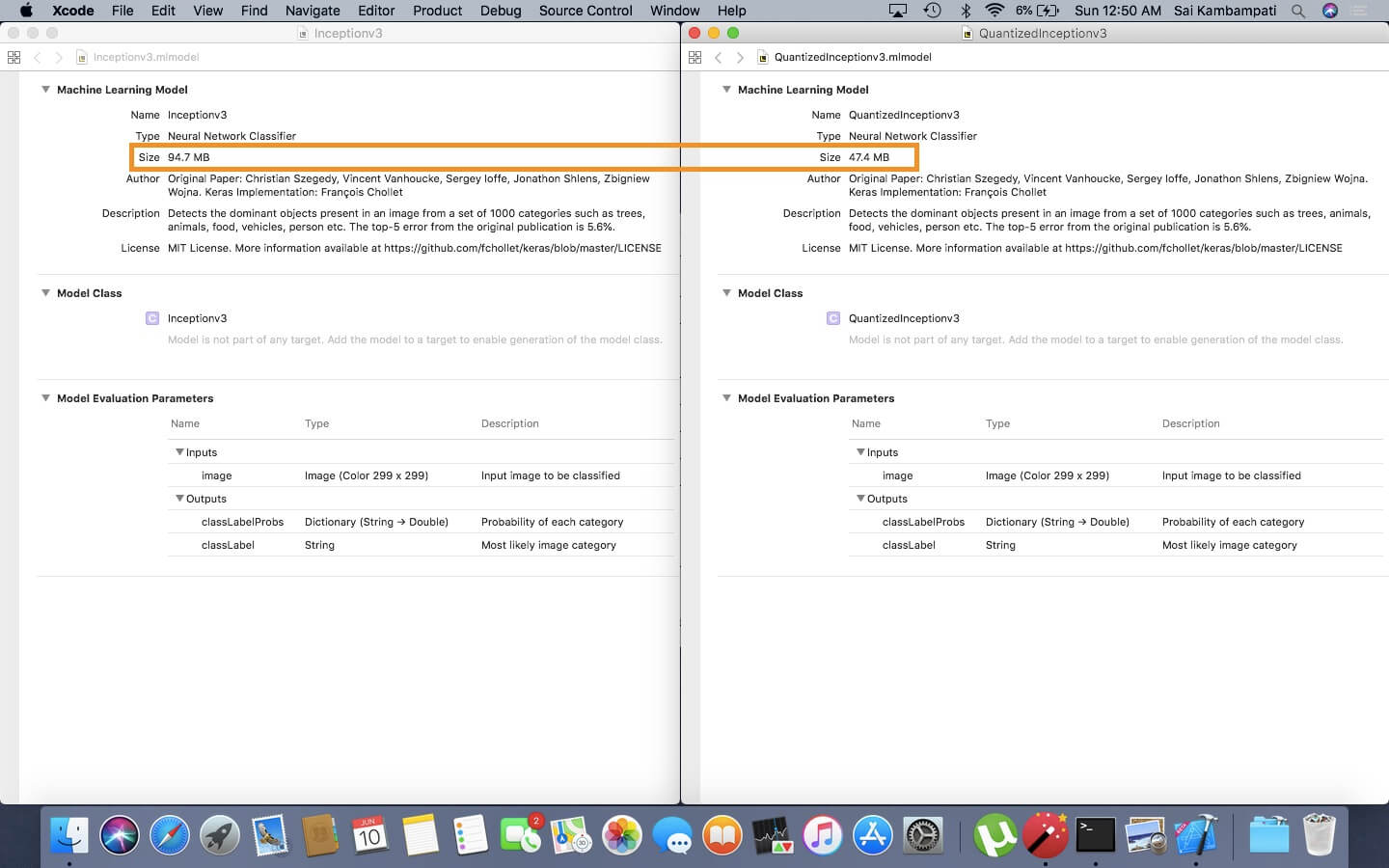
我們可以看到範例 Inceptionv3 模型的數據以 16 位元來表示時,使用的儲存空間較少!
然而,最重要的是被量化後權重的真正意義。在我前文的比喻中,我說過權重數量越多,結果更精確。當我們試著量化一個模型時,模型的精確度亦會隨著權重數量多寡而減少。換而言之,量化就會犧牲精準度。量化後的模型與權重大小近似,因此運行量化後的模型並檢測其精準度是非常重要的。
我們當然是希望在量化模型的同時,保持最高可能的精確度;這點只要找到對的量化演算式就可以做到了。在之前的範例,我們使用了線性量化權重的方法,現在讓我們試著改用權重查表的方法來看看。跟之前一樣,我們在命令視窗中輸入下列程式碼:
lut_quant_model = quantize_weights(model, 16, "kmeans")

當模型被量化完成後,我們需要利用一些樣本數據,將 lin_quant_model 與 lut_quant_model 兩個結果與原來的模型做個比較。用這樣的方式,我們就可以找出哪一個模型量化後與原來的模型最相似。請在這裡把樣本影像的整個目錄下載下來(目錄被命名為 Sample Images)。輸入下列指令,我們就可以得知哪一個模型執行的結果最滿意!
compare_models(model, lin_quant_model, '/Users/SaiKambampati/Desktop/SampleImages')
這可能需要花點時間,但當兩個模型比較完成後,你會看到這樣的輸出:
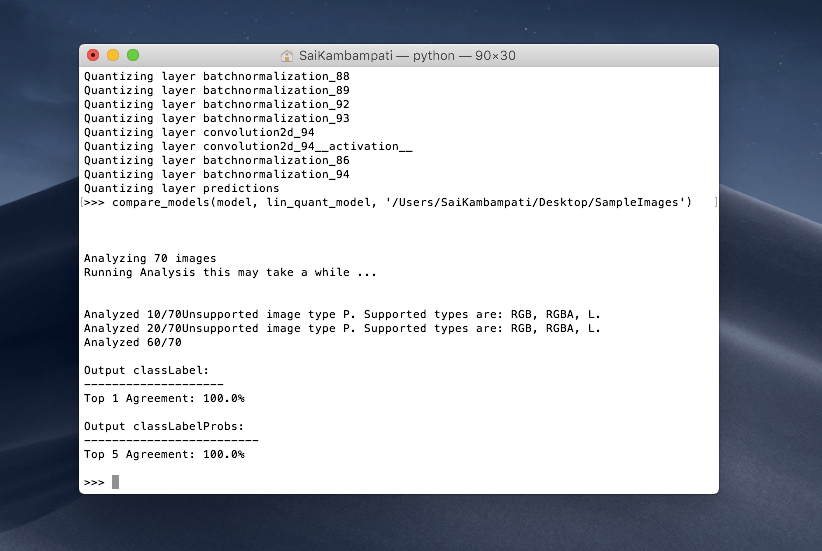
在顯示中,我們會對 Top 1 Agreement 這結果較有興趣。它顯示為 100%,這表示它與我們的模型相似度為 100%!這對我們來說是個好消息,因為我們已找到一個被量化的模型,佔用的空間較小,而且與原來的模型精確度幾乎一樣。若我們想的話,我們現在就可以將這結果整合到項目中,但讓我們也比較看看量化查表方法所產出的模型。
compare_models(model, lut_quant_model, '/Users/SaiKambampati/Desktop/SampleImages')
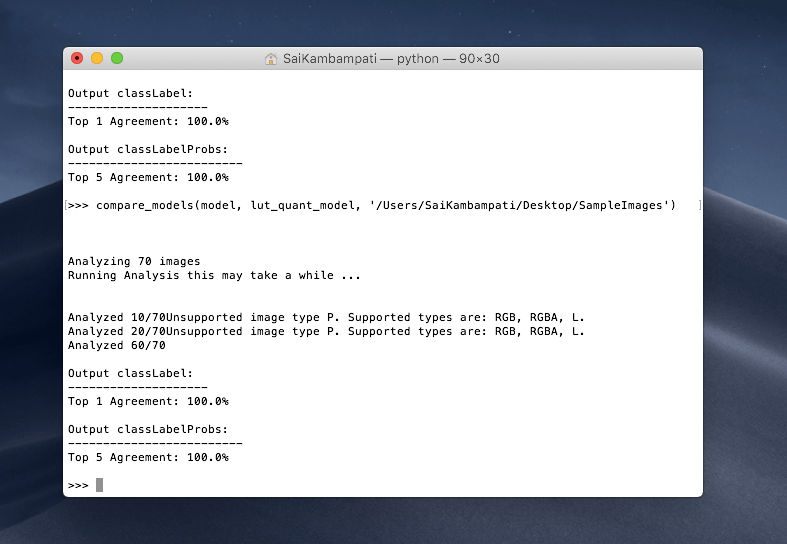
這個模型亦同樣有 100% 的輸出結果,表示這兩個模型是相容的!我鼓勵你試著量化不同的模型。在上面的範例中,我們量化 Inceptionv3 這模型到 16 位元。若你繼續量化這模型到 8 位元、或甚至是 4 位元,再與樣本資料來比較,結果又會是如何呢?
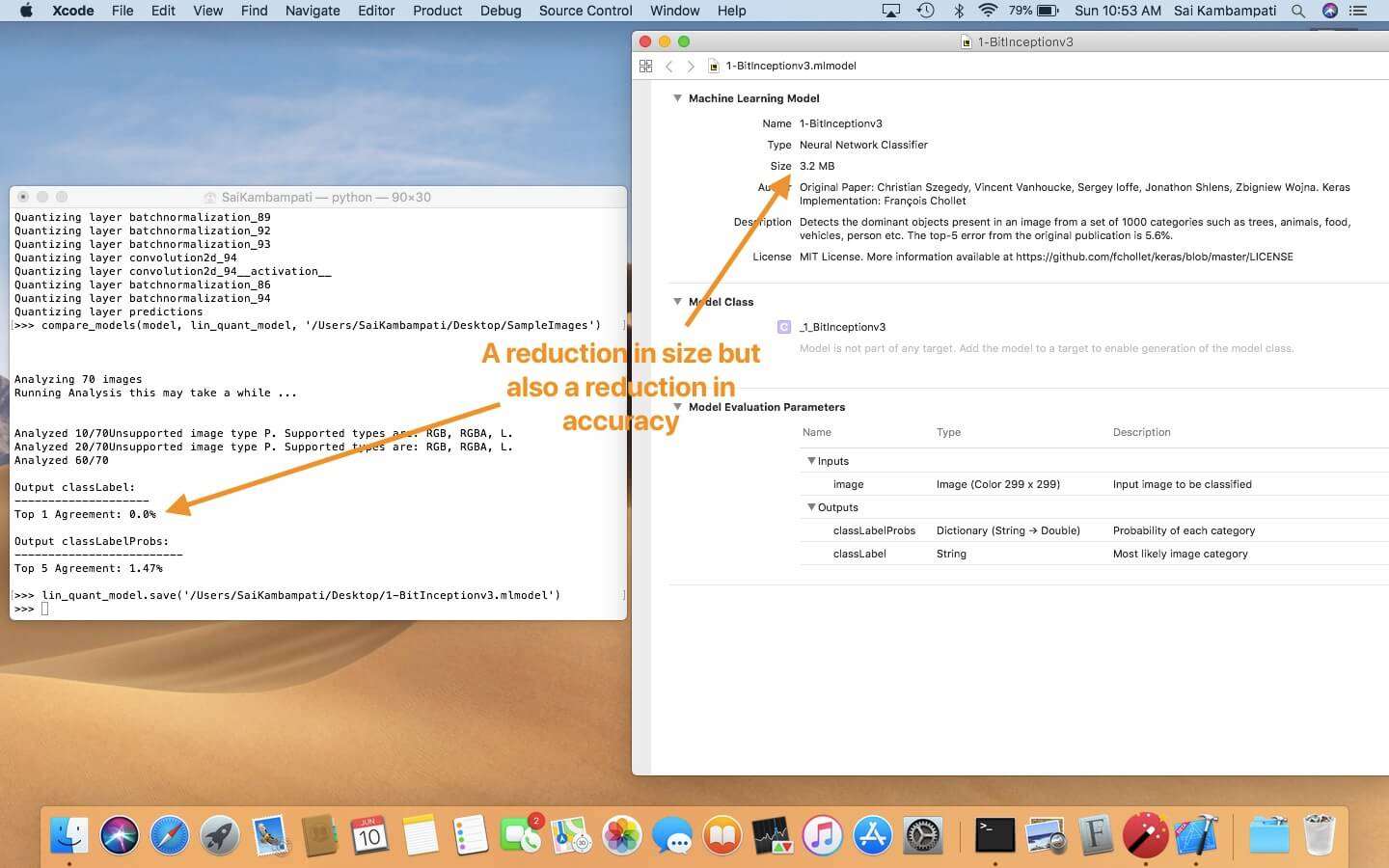
上圖說明了使用線性演算法來量化 Inceptionv3 到 1 位元表示時的結果,你可以看到模型的大小神奇地減少了很多,但同樣地它的精確度也降低了。事實上,它顯示出 0% 精確度,也說明這量化後的模型完全不精確。試著玩玩不同的量化方法,找出最適合的一個。請務必記住,你需要測試量化後的模型來確保它的精確度。
效能 (Performance)
Apple 所關注的另一個重點,就是 Core ML 2 的效能。既然 ML 運算是在裝置上執行的,我們當然希望它執行時又快又精確。這可能相當複雜,但幸運的是 Apple 提供了方法來改善 CoreML 模型的效能。讓我們以範例來一步步說明。
形式轉換 (Style Transfer) 是一種機器學習的應用程式,它基本上是將一個影像轉換成另一種形式的影像。如果你之前有用過 Prisma 這應用程式,就知道它也是形式轉換的一種應用。
若我們要深入研究形式轉換的神經網路,我們就會注意到有幾組輸入資料適合這演算法。在神經網路中,每一層都會針對原來的影像增加一些影像轉換。這意味著此模型必須將每一個輸入資料,映射出一個輸出值,並從這輸出值中,產生出一個臆測值 (Prediction),而這臆測值可被用來產生權重。但這些在程式碼中要如何演釋 ?
// Loop over inputs
for i in 0..< modelInputs.count {
modelOutputs[i] = model.prediction(from: modelInputs[i], options: options)
}
在上面的程式碼中,你可以看到每項輸入,我們都會要求模型去產出臆測值,而依據一些 options 來產出結果。然而,依據每項輸入來產出的方式會耗費很多時間。
為克服這現象,Apple 引進全新的處理方式 Batch API!與 for-loop 不同,在機器學習中的批次處理是將所有輸入餵給模型,然後產生精確的臆測值。這樣花的時間就更少,而更重要的是要寫的程式碼也較少。
這裡將上面 for-loop 程式碼用新的 Batch Predict API 來改寫!
modelOutputs = model.prediction(from: modelInputs, options: options)
大功告成!只要一行程式碼就搞定了!你可能會說:「等等,我之前沒有這樣做過啊!這聽起來很複雜,我在哪裡才能用這方式?」這疑問讓我帶出最後的一點 ── 客製化。
客製化 (Customization)
打開神經網路,你可以看到它們是由很多層別組成的。然而,當你試著將用 Tensorflow 或是 Keras 寫的神經網路轉換到 Core ML 上時,你會發現有很多腳本 (Scenarios)。不過,總有些時候 Core ML 沒有任何工具可以正確地將這些模型轉換過來啊!這代表甚麼呢?就讓我們用另外一個範例來說明吧。
影像識別模型是以卷積神經網路 (Convolutional Neural Network, CNN) 來建立。CNN 包含一連串的層別,而且每個層別都被最佳化。當你要將神經網路由以某種儲存格式轉換到 Core ML 時,你其實是在轉換每一層的數據。然而,一些罕見的腳本,Core ML 就沒有提供工具來轉換這些層別。以前,你遇到這現象就束手無策了,但在 iOS 12 平台上 Apple 工程師引進 MLCustomLayer 協定,允許開發者在 Swift 創建自己的層別。有了 MLCustomLayer,你可以定義 Core ML 模型內神經網路層的行為。不過,客製化層別只適用在神經網路的模型上是毫無意義的。
到目前為止這聽起來很複雜,別擔心。這通常需要一個有此技能的資料科學家、或是 ML 工程師來了解所有神經網路的複雜面,並有此方面的天份寫出他們自己的模型。這已經超出本教學範圍,所以我們不必深入研究它。
結論
以上就總結了 Core ML 2.0 帶來新的改變。Core ML 2.0 旨在讓模型更小、執行速度更快、並有更多客製化功能。 我們可以看到權重量化如何減少 Core ML 模型的大小、利用新的 Batch API 來改善模型的效能、以及為模型寫客製化層別的範例。身為開發者,我可以預見你將會使用權重量化的方法,多於使用其他的兩種技巧(Batch API 與客製化層別)。
若你想要更深入探索 Core ML 2.0,這裡有些很棒的資源可供參考:
- What's New in Core ML, Part 1 - WWDC 2018
- What's New in Core ML, Part 2 - WWDC 2018
- Vision with Core ML - WWDC 2018
- Introducing Natural Language Framework - WWDC 2018
- Core ML Documentation
- Apple's Machine Learning Page
原文:Introduction to Create ML: How to Train Your Own Machine Learning Model in Xcode 10